Coding practice #3: Due midnight, November 4
files needed = ('banking_data.csv', which you created in CP #2; 'two_digit_by_port.csv', 'toys.csv')
Answer the questions below in a jupyter notebook. You can simply add cells to this notebook and enter your answers. When you are finished, upload the completed notebook to canvas.
My office hours are Tuesdays 9:00AM-10:00AM and Tuesdays 3:30PM-4:30PM in 7444 Soc Sciences. Satyen's are Mondays 3:00PM-4:00PM in 6413 Soc Sciences and Mitchell's are Thursdays 3:00PM-4:00PM in 7308 Soc Sciences.
You should feel free to discuss the coding practice with your classmates, but the work you turn in should be your own.
Cite any code that is not yours: badgerdata.org/pages/citing-code
Read the class policy on AI: badgerdata.org/pages/ai
Exercise 0: Last, First
Edit the heading in this cell to add your actual name. Enter it as: last name, first name.
Exercise 1: Making subplots
Note: This exercise uses the banking_data DataFrame created in coding practice 2 in Exercise 2.
The U.S. banking industry has become increasingly concentrated over the years, especially due to a wave of mergers and acquisitions that occurred in the 1990s and 2000s. Furthermore, many commercial banks have begun to close their physical branch locations due to the rise of online and mobile banking. (See this article from Forbes.)
In this exercise, you will create three time series plots of the number of banks, number of offices, and number of offices per bank between 1934 and 2017.
Part (a): Load data
- Open your notebook from coding practice #2. Run your code for exercise 2. You should have a DataFrame named
banking_data. - Save
banking_datato a csv file named 'banking_data.csv'. - In a new cell below, read 'banking_data.csv' into a DataFrame named
banking_data
Part (b): Make subplots
- Create a figure with three subplots (three rows in a single column). Set the figure size to (15, 15).
- In the first subplot, create a line plot of the number of banks by year. Make the line dotted and black. Label the y-axis 'Number of banks'. Set the title of this subplot to 'Number of U.S. commercial banks, 1934-2017'.
- In the second subplot, create a line plot of the number of offices by year. Make the line dashed and red. Label the y-axis 'Number of offices'. Set the title of this subplot to 'Number of offices of U.S. commercial banks, 1934-2017'.
- In the third subplot, create a line plot of the average number of offices per bank. Make the line blue with a dash-dot pattern. Label the y-axis 'Number of offices per bank'. Set the title of this subplot to 'Average number of offices per bank, 1934-2017'.
Part (c): Make a single plot
Create a new figure that plots the three time series above on the same plot. Set the figure size to (15, 5). Maintain the same line color and pattern for each series as above, and add a legend with labels for each line.
Is this a good example of graphical excellence?
Part (d): The dual-axis method
Let's put the 'number of offices per bank' and the 'number of banks' variable on the same subplot with two different y-axes. Your figure should look something like this one.
- Use the
.twinx()method of matplotlib (docs) to plot the number of banks on the left axis and the number of offices per bank on the right axis. - Add all of the labels that you need.
Exercise 2: Dates and APIs
More work with U.S. GDP. The data come from FRED, which we will access via an API call.
Part (a): Retrieve data from FRED
- Use pandas datareader to create a DataFrame named
gdpwith the variable GDPC1 from FRED. Set the start date to 1950 and do not specify an end date. This will return 1950 up to the most recent observation available. - Compute the growth rate of 'GDPC1'
- Print out the first 3 rows of your DataFrame
Insert a markdown cell below your code cell and answer:
- What type of index does your DataFrame have?
- What is the frequency of the data?
Part (b): Plot the growth rates
- Plot gdp growth rates against the dates
- Add a horizontal line at y=0. Make the line black with width 0.75.
- Add labels as needed
Part (c): Downsample to yearly frequency
- Use the
resample()method to create a new variable that holds the annual value of gdp. The quarterly data we are working with are expressed as annual rates. (By annual rates, we mean that the quarterly value is multiplied by 4.) Which aggregator function should you use:mean()orsum()?
Part (d): Plot the annual data
- Plot annual real gdp
- Add labels as appropriate
Exercise 3: multiIndex
Let's practice using a multiIndex to select observations from data with multiple dimensions. The file 'two_digit_by_port.csv' contains U.S. the dollar value of imports by two-digit commodity code and port of entry for December 2013.
For example, imports into port number 3703 (Green Bay, WI) of commodity 72 (Iron and Steel) were $9,208,917 in December 2013.
You can learn about port codes here.
The data were retrieved from the Census trade API.
Part (a): Load the data
- Load 'two_digit_by_port.csv' into a DataFrame
- Check the data types.
I_COMMODITYshould be integers andGEN_VAL_YRshould be floats. All others should be objects.
Part (b): Set up the index
- Set the index to be
PORT,I_COMMODITY, andI_COMMODITY_SDESC, in that order. - Sort the index
- Print out the first 3 and last 3 rows of the DataFrame
Note that the - port is the total for all ports. This is why PORT is an object and not an int.
Part (c): Partial indexing
- Use the index to retrieve all the rows for ports 3002 (Tacoma, WA) and 3902 (Peoria, IL) and create a DataFrame named
part_cfrom those rows. [Hint: The ports are the outermost index. Try.loc[].] - Print out the number of rows in
part_c.
Part (d): Indexing
- Print out the row that corresponds to port = 3002 and commodity code = 95 (toys and games).
Part (e): Partial indexing
- Retrieve all the rows that correspond to commodity code = 87 (Vehicles) and create a DataFrame from those rows named
part_e. - Print out the first 4 rows of
part_e.
You might want to use the .xs() method here.
- Drop the row that corresponds to port = '-' from
part_e. -
Print out the first 4 rows of
part_e. -
Report the total value of imports of vehicles from
part_e. Report the number using commas to separate the thousands and no digits to the right of the decimal point. -
Report the total value of imports of vehicles reported by port = '-'. Report the number using commas to separate the thousands and no digits to the right of the decimal point.
Does it match your answer from part 5?
Exercise 4: Plot customization (Challenging)
Below is a figure I created for a panel I participated in at the Atlanta Federal Reserve Bank. The panel was about supply chains. I wanted to show how retailers have changed their ordering timing in light of delays. The figure is about imports of children's toys. There was a clear restocking cycle before the pandemic: Firms began increasing orders of toys in July with the peak orders happening in October to meet demand for holiday gifts. In 2022, restocking has started earlier.
The file 'toys.csv' contains the data on imports of children's toys to the United States. I retrieved the data from the Census trade api that we discussed in class.
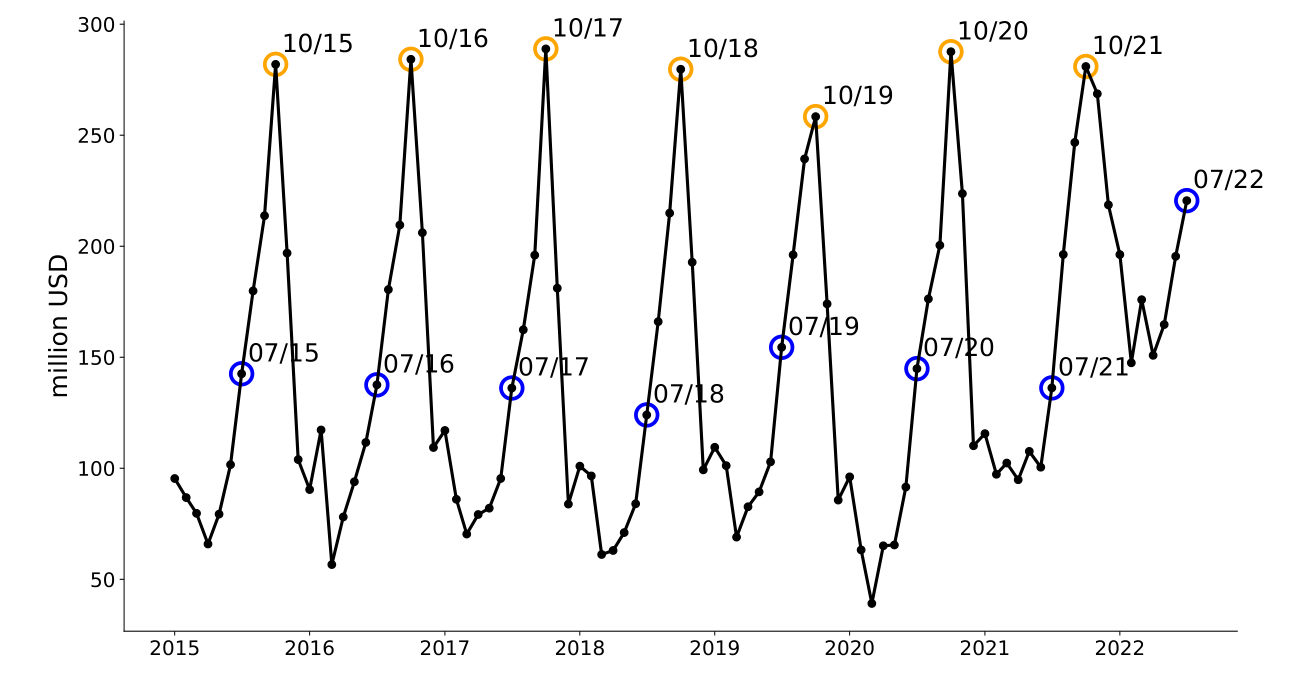
Part (a): Plot the data
-
Plot the import values and set the line color and markers.
-
line widths are 2.5
- axis label font size is 20
- tick label font size is 16
- the text on the figure has font size 20
Part (b): Add the circles
Now comes the harder parts. There may be other ways to do it. Here is how I did it.
- The orange circles are a scatter plot of only the October dates. I set the marker size to '300' and used a line width of 3.
- The blue circles are a scatter plot of only the July dates. I set the marker size to '300' and used a line width of 3.
Part (c): Add the labels
I used a loop and the .annotate() to add the labels.