download notebook
view notebook w/o solutions
What makes a good visualization?
files needed = ('bea_gdp.csv', 'map_data.zip')
Visualizations of data are probably the most important outputs data analysts will produce. We may spend a lot of time building complex models and cleaning datasets, but when it comes to communicating our results, a visual display is often most efficient. Your results are only useful when they can be understood by others.
In this notebook, we are taking a step back from the nitty-gritty (no, not that one) of coding figures to spend some time thinking about what makes a "good" visualization. While the code to create the figures is in this notebook, we won't worry about it (we will cover it in other notebooks) and focus on the figures themselves. [Don't despair, you will get a chance to code in the practice problems.]
Today we will cover:
- Why visualize? What is graphical excellence?
- The big picture: Know your message, your audience, and your medium.
- Plot types: Match your plot type to your message.
- Graphical concepts and best practices
Why visualize?
Below, we load some data on U.S. GDP and its subcomponents. I have displayed the data from 2010 onward as a table. After looking at the table, answer these questions:
Is the correlation between investment spending (inv) and GDP (gdp) positive or negative? Is the relationship linear?
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
gdp = pd.read_csv('bea_gdp.csv', index_col='year')
gdp.loc[gdp.index>=2010]
| gdp | cons | inv | exp | imp | gov | res | |
|---|---|---|---|---|---|---|---|
| year | |||||||
| 2010.0 | 15598.8 | 10643.0 | 2216.5 | 1977.9 | 2543.8 | 3307.2 | -11.3 |
| 2011.0 | 15840.7 | 10843.8 | 2362.1 | 2119.0 | 2687.1 | 3203.3 | -3.7 |
| 2012.0 | 16197.0 | 11006.8 | 2621.8 | 2191.3 | 2759.9 | 3137.0 | 0.0 |
| 2013.0 | 16495.4 | 11166.9 | 2801.5 | 2269.6 | 2802.4 | 3061.0 | -0.4 |
| 2014.0 | 16912.0 | 11497.4 | 2959.2 | 2365.3 | 2942.5 | 3033.4 | 0.7 |
| 2015.0 | 17432.2 | 11934.3 | 3121.8 | 2375.2 | 3094.8 | 3088.2 | 11.3 |
| 2016.0 | 17730.5 | 12264.6 | 3074.8 | 2382.3 | 3145.9 | 3144.4 | 22.3 |
| 2017.0 | 18144.1 | 12587.2 | 3183.4 | 2475.5 | 3292.4 | 3172.3 | 20.8 |
| 2018.0 | 18687.8 | 12928.1 | 3384.9 | 2549.5 | 3427.2 | 3229.8 | 1.1 |
| 2019.0 | 19091.7 | 13240.2 | 3442.6 | 2546.6 | 3464.2 | 3303.9 | -25.0 |
If you are anything like me, you probably have no idea how to answer these questions by looking at a table of numbers.
Now take a look at this figure.
-
Is the correlation between investment spending (inv) and GDP (gdp) positive or negative? Positive!
-
Is the relationship linear? Pretty much!
All the information that is in this figure is in the table of numbers from above.
Key idea: Visualizations are powerful ways to summarize large amounts of data.
fig, ax = plt.subplots(figsize=(10,5))
ax.scatter(gdp.loc[gdp.index>=2010,'gdp'], gdp.loc[gdp.index>=2010,'inv'], # line plot of gdp vs. time
color='black' # set the line color to black
)
ax.set_ylabel('investment (billions of dollars)')
ax.set_xlabel('gross domestic product (billions of dollars)')
ax.set_title('U.S. investment spending and gdp')
#ax.set_xlim(0, 20000)
sns.despine(ax=ax)
plt.show()

Graphical excellence
You will sometime catch me saying: "That is a pretty figure." This is an example of me being imprecise with language. I do not mean that the figure is pretty in an artistic sense—that it is an interpretation of humanity or an expression of the imagination—what I mean is that the figure is graphically excellent.
Edward Tufte's The Visual Display of Quantitative Information is a masterpiece of "thinking hard about visualizations." The book is worth a read (or a look through). His Principles of Graphic Excellence are great to keep in mind. Two of my favorites:
- Graphical excellence consists of complex ideas communicated with clarity, precision, and efficiency
- Graphical excellence is that which gives the viewer the greatest number of ideas, in the shortest time, with the least ink, in the smallest space.
Let us all strive for graphical excellence.
What follows is a distillation of ideas from several sources as well as my own thoughts. I encourage you to look through these sources, too.
-
Ten Simple Rules for Better Figures (Rougier, Droettboom, and Bourne, 2014). The big picture discussion below is based on some of their rules. My favorite is: Do not trust the defaults. Not long, ago, this was Excel's default chart formatting.
-
Cole Nussbaumer Knaflic's Storytelling with Data. The book is a bit verbose for my tastes, but full of good advice.
-
Data Visualization: Rules and Guidelines from the QuantEcon group. This entire website is good.
{kind=link}
The big picture
We spend a lot of time on the details of our visualizations: data wrangling, formatting axes, choosing colors, labeling...
Before working out the details of a visualization, we need to take a step back and get a handle on the big picture:
- Your message
- Your audience
- Your medium
1. Know your message
This is the most important part of any visualization. All of the decisions you make regarding the details of the figure will be made in support of your message. What message are you trying to convey? Some examples:
- I want to show how a variable changed over time.
- I want to compare a variable in two geographic locations.
- I want to show how two variables are related to each other.
- I want to show that something is big or small.
As a general rule, each visualization should have one message. When you are deciding to include a figure in a project ask yourself: "What do I want the reader to learn from this?"
2. Know your audience
Are you writing for an academic audience with a background in the subject? Are you writing for someone who knows a bit about statistics but nothing about your subject? Are you writing for the average reader of the Wall Street Journal? Of a blog?
Defining your target audience will help keep your visualization appropriate. If you are writing for a general audience, you might not include the variance and autocorrelation of a variable—it's wasted ink. If you are writing for a math-literate audience, you probably do not need to explain what a log axis means. Your audience will be one factor in determining which details to include and which to leave out.
3. Know your medium
Where do you intend to publish your visualization? On paper? On the web? In a magazine?
This is particularly important to keep in mind when you are thinking about color in a figure and whether to include fine details.
When I am writing a research paper, I expect it to be printed out on paper for someone to read. This often happens in black-and-white, so I make sure my figures can be understood without color. Figures in a paper are usually only a few square inches, so I try to avoid small details that would be hard to read without magnification.
When I make figures for a seminar presentation that will be projected onto a screen, I use color when it is useful. The large format of the figure also means that I can include more details, but those details have to be useful in supporting my message. Otherwise, I leave them out!
In many cases, I make two versions of the same figure: one for the paper and another for the presentation.
Plot types
Our message will largely drive the type of visualization we will use. There are many to choose from: The Data Visualization Catalog provides an extensive list of plot types.
In general, I use only a handful of plot types, and if you read the New York Times, The Wall Street Journal, The Economist, etc., you will notice the popularity of just a few types of visualizations:
- Line plots
- Scatter plots
- Bar plots
- Histograms
- Maps
We briefly review these below. Again, we are not focusing on the code today. We are focusing on the design of the figure. We begin with data on the components of U.S. gross domestic product.
1. Line plots
Line plots are good for showing the evolution of a variable over many time periods. Typically, time is on the x axis and the variable of interest in on the y axis. Although we only have data at each year, we connect the points with a line. This is reflecting the idea that we think the variable is growing continuously over time.
If we only have data for a few points in time we might be better off with a bar chart (see below). The issue is that it is harder to interpolate (draw the line) between the few points.
Below, we plot U.S. GDP from 1929 to 2019. Time is on the x axis and GDP is on the y axis.
The message: GDP has grown a lot since 1929. The shape of the curve suggests that the growth is exponential.
fig, ax = plt.subplots(figsize=(10,5))
ax.plot(gdp.index, gdp['gdp'], # line plot of gdp vs. time
color='black' # set the line color to black
)
ax.set_ylabel('billions of dollars')
ax.set_title('U.S. Gross Domestic Product')
sns.despine(ax=ax)
plt.show()

Variants: Add markers, labels, or a legend. Use a log axis to make the exponential nature of growth more apparent.
2. Scatter plots
Scatter plots are good for showing the relationship between two variables. Each point corresponds to an (x,y) pair. Below, we plot aggregate investment spending (y-axis) and gdp (x-axis).
The message: Investment is positively correlated with GDP. The relationship is roughly linear.
fig, ax = plt.subplots(figsize=(10,5))
ax.scatter(gdp['gdp'], gdp['inv'], # line plot of gdp vs. time
color='black' # set the line color to black
)
ax.set_ylabel('investment (billions of dollars)')
ax.set_xlabel('gross domestic product (billions of dollars)')
ax.set_title('U.S. investment spending and gdp')
ax.set_xlim(0, 20000)
sns.despine(ax=ax)
plt.show()

Variants: Add a regression line. Scale the points against a third variable.
Below we add the regression line using the seaborn package. Now the message "the relationship is linear" is even more apparent.
my_fig, my_ax = plt.subplots(figsize=(10,5))
sns.regplot(x='gdp', y='inv', data=gdp, ax = my_ax, color = 'black', ci = 0)
sns.despine(ax=my_ax)
my_ax.set(xlabel='gross domestic product (billions of dollars)', ylabel='investment (billions of dollars)')
ax.set_title('U.S. investment spending and gdp')
my_ax.set_xlim(0, 20000)
plt.show()

3. Bar plots
Bar plots are good for comparing the values of relatively few, discrete observations. They are almost always preferred to a pie chart. [I cannot think of a case in which I would rather use a pie chart, but I'm leaving myself some wiggle room.]
Below we plot the average GDP growth rate over two-decade intervals. We only have five data points.
The message: GDP growth in the 1920s and 30s was low, peaked in the 40s and 50s, and has drifted lower since.
# Compute the GDP growth rate.
gdp['gdp_gr'] = gdp['gdp'].pct_change()*100
# Create 20-year bins.
gdp['long_period']=pd.cut(gdp.index, bins=range(1920,2021,20))
# Take average over these 20-year bins.
gdp_long = gdp.groupby('long_period').mean()
fig, ax = plt.subplots(figsize=(10,5))
ax.bar(gdp_long.index.astype(str), gdp_long['gdp_gr'], color='silver')
ax.set_ylabel('GDP growth rate (percent)')
ax.set_title('U.S. GDP growth')
sns.despine(ax=ax)

Variants: horizontal bar plots.
4. Histograms
Histograms are good for visualizing the distribution of a variable. In what range are the values concentrated? What are the minimum and maximum values? Histograms are typically displayed as bars. Each bar represents an interval of the values (often called bins) a variable can take and the height of the bar reports how often the data are in this interval. The x axis measures the values of the variable and the y axis measures the frequency of the value.
Below, we plot the histogram of U.S. GDP growth rates.
The message: GDP growth is often in the range of zero to five, but there have been large growth rates, both positive and negative.
fig, ax = plt.subplots(figsize=(10,5))
ax.hist(gdp['gdp_gr'].dropna(), color='silver', density=True, rwidth=0.95)
ax.set_ylim(0, 0.1)
sns.despine(ax=ax)
ax.set_xlabel('GDP growth rate (percent)')
ax.set_ylabel('density')
plt.show()

Variants: Kernel density plots, which estimate a continuous pdf from the data. Adding a line to represent the mean of the data.
5. Maps
Maps are useful for displaying the spatial dimension of data. How is a variable distributed geographically? Is it concentrated in one part of the country? (e.g., housing prices are most expensive on the coasts; corn is mostly grown in the midwest) Is a variable correlated with geographic features? (e.g., truck stops are located near highways; bars are located near universities)
Below, we plot the cumulative number of covid-19 cases per capita, by county, in Wisconsin. Is there a spatial relationship in the spread of the virus?
The message: There are three clusters of cases. One around Menominee County, one around Jackson County, and one around Dodge County.
import geopandas as geo
map_data = geo.read_file('map_data')
fig, ax = plt.subplots(figsize=(10,8))
lkwds={'label': 'Cumulative cases per capita (percent)'}
map_data.plot(ax = ax, column='PCT_INF', cmap='Reds', legend=True, legend_kwds = lkwds)
plt.axis('off')
plt.show()
C:\Users\kimru\anaconda3\envs\geo3\lib\site-packages\pyproj\__init__.py:91: UserWarning: Valid PROJ data directory not found. Either set the path using the environmental variable PROJ_LIB or with `pyproj.datadir.set_data_dir`.
warnings.warn(str(err))

Practice problems
Use markdown cells to write out your answers to the practice problems.
1. Match the message to the plot type
For each of the messages below, choose the appropriate plot type. Describe what variable would be on each axis, if applicable.
You have daily data on the temperature in Madison, WI and the number of bikes that crossed the bike counter at Regent St and Monroe St.
- I want to show that the temperature is coldest in January and February.
- I want to show that fewer people ride bikes when the weather is cold.
You have data on the locations for Walmart distribution centers and Walmart stores. You also have data on the population density of the counties in which Walmart stores are located.
- I want to show that Walmart stores cluster around Walmart distribution centers.
- I want to show that Walmart stores are located in "medium" density locations and not in extremely dense cities like New York.
Solution:
- I might use a line plot, with time on the x axis and temperature on the y axis. Temperature data may be noisy. I might plot the moving average of the temperature to make it easier to see the trends.
A second approach would be a bar plot, with the average temperature by month in each bar.
-
I would use a scatter plot, with number of riders on the y axis and temperature on the x axis. In this case, which variable goes on which axis is not important.
-
I would use a map. I would use one color or shape for the markers for Walmart distribution centers and a different color or shape for the stores. See this paper by Tom Holmes. He was constrained to black and white for his figures. Could you have improved them? I might have used fewer time periods so that I could have larger maps that made it easier to see the detail. In a presentation I would have used color.
-
I would use a histogram with the density of the county on the x axis. The y axis would show how often a Walmart was located in a density bin. The histogram would show that very few stores are located in very high density counties.
2. Know your medium
Visualizations meant for online distribution are often interactive. Hovering over parts of the figure pop up additional information. Here is an example that tracks the COVID cases.
- What are the benefits of creating an interactive visualization?
- What are the potential problems with an interactive visualization?
Solution: 1. The biggest benefit is that the user can get more information without cluttering the visualization. I can hover over a part of the plot that interests me and see exactly what the value is at that point. To know this in a non-interactive figure, there would need to be data labels next to each point, or a very precise axis.
- One potential problem is that the user gets lost in the details and misses the bigger picture. In the map I might get caught up trying to see what the value is for Dane county and miss the point that case loads are high in the Northwest and middle South. A second potential issue is mobile devices. If you view an interactive graphic on a small cellphone screen, it may be hard to zoom and scroll.
Graphical concepts: Best practices
There are hundreds of details, rules, and best practices regarding visualization, but, as in most things, a few simple things make a big difference.
- Clutter: spines and boxes
- Legends and labels
- Color
- Axes formats
1. Clutter
Remember Tufte's principle of "the least ink." Every mark in a figure should be doing something. If it is not, it is clutter and should be eliminated. This is the golden rule of visualization.
Boxes around figures (which are made up of four "spines") are inexplicably the default behavior of many plotting packages, including matplotlib. Compare the images below.
Do the top and right spines help you better understand the GDP figure? They do not, so I remove them. You can turn off spines individually:
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
or use the seaborn package
import seaborn as sns
sns.despine(ax=ax)
In the map example, it's even worse. Do you need to know the coordinate values in the map? Is our goal to navigate to Woodruff, WI? It is more efficient to just turn the axes off.
plt.axis('off');
fig, ax = plt.subplots(2, 2, figsize=(12,10))
for a in range(0,2):
ax[0][a].plot(gdp.index, gdp['gdp'], color='black')
ax[0][a].set_ylabel('billions of dollars')
ax[0][a].set_title('U.S. Gross Domestic Product')
sns.despine(ax=ax[0][1])
lkwds={'label': 'Cumulative cases per capita (percent)'}
map_data.plot(ax = ax[1][1], column='PCT_INF', cmap='Reds', legend=True)
map_data.plot(ax = ax[1][0], column='PCT_INF', cmap='Reds', legend=True)
plt.axis('off')
plt.show()

2. Legends and labels
In the figures below, I have added investment spending to our gdp figure. How do we tell the two apart? One way is to use a legend. Notice that the default legend has a box around it. More clutter. We turn the box off with
ax.legend(frameon=False)
An alternative approach is to add labels directly to the figure. This approach has two big advantages. First, the reader does not need to look back-and-forth between the legend and the lines to keep track of which line is which. Second, I do not need to rely on color or different line styles to differentiate the lines.
ax[1].text(1980, 9500, 'gdp')
ax[1].text(1980, 2600, 'investment')
This approach is not always applicable. If the lines are very close to each other, if there are many lines, or if the lines overlap, then it may be preferable to use a legend.
fig, ax = plt.subplots(1, 2, figsize=(12,5))
for a in range(0,2):
ax[a].plot(gdp.index, gdp['gdp'], color='black', label='gdp')
ax[a].set_ylabel('billions of dollars')
ax[a].set_title('U.S. GDP and Investment')
sns.despine(ax=ax[a])
ax[0].plot(gdp.index, gdp['inv'], color='black', ls='--', label='investment')
ax[0].legend()
ax[1].plot(gdp.index, gdp['inv'], color='black', ls='-', label='investment')
ax[1].text(1980, 9500, 'gdp')
ax[1].text(1980, 2600, 'investment')
plt.show()

3. Color
More than once I have asked someone why they used a color in their plot and they replied "because it looks good." We are not making art here! We should be using color to make our figures more informative. The links at the top of this notebook contain more on color choice and representing color in computer graphics is fascinating in its own right. I want to just cover a few basics here.
I mostly use color to
- Differentiate variables in a figure with many variables
- Indicate the value of a variable in a choropleth map
I never use color
- In the background. Some people will use a very light gray as background in the plot. ggplot, seaborn, and FiveThirtyEight include gray backgrounds in their default style. If you think a gray background makes it easier to interpret your plot, then go for it.
Differentiating variables
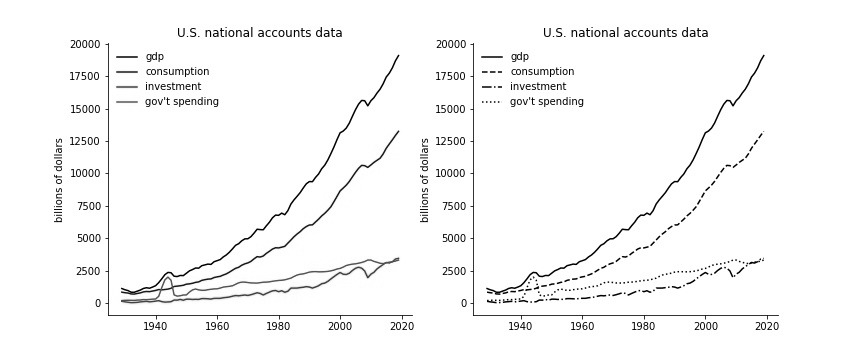
In the figure below, I add more variables of the U.S. national income and product accounts. I try two different methods to differentiate the variables.
fig, ax = plt.subplots(1,2,figsize=(12,5))
ax[0].plot(gdp.index, gdp['gdp'], color='black', label='gdp')
ax[0].plot(gdp.index, gdp['cons'], color='blue', label='consumption')
ax[0].plot(gdp.index, gdp['inv'], color='red', label='investment')
ax[0].plot(gdp.index, gdp['gov'], color='green', label='gov\'t spending')
ax[1].plot(gdp.index, gdp['gdp'], color='black', label='gdp')
ax[1].plot(gdp.index, gdp['cons'], color='black', ls='--', label='consumption')
ax[1].plot(gdp.index, gdp['inv'], color='black', ls='-.', label='investment')
ax[1].plot(gdp.index, gdp['gov'], color='black', ls=':', label='gov\'t spending')
for a in range(0,2):
ax[a].set_ylabel('billions of dollars')
ax[a].set_title('U.S. national accounts data')
ax[a].legend(frameon=False)
sns.despine(ax=ax[a])
plt.savefig('color.jpg')
plt.show()

The color makes it easier to tell the lines apart, especially in the early periods, when the lines are close together and some overlap. The figure on the right takes more work to sort out which line pattern corresponds to which variable.
Warning
Suppose we include this figure in a pdf which someone prints out on a laser printer in black and white. The figure will be converted to grayscale for printing. Now, the left panel is useless. Know your medium.
Mapping colors
The second place I tend to use color in visualizations is to plot a variable in "color space." The choropleth map of covid cases from above is a good example (heatmaps are another). They key here is the choice of colormap. A colormap is a sequence of colors that are mapped to the values of a variable. In the covid map case, the colormap uses different intensities of the color red to indicate the value of the covid infection rate. The higher the value in the data, the darker the color red.
There are different types of colormaps that are good for different kinds of data. From the excellent colormap tutorial at matplotlib:
Sequential: change in lightness and often saturation of color incrementally, often using a single hue; should be used for representing information that has ordering.
Diverging: change in lightness and possibly saturation of two different colors that meet in the middle at an unsaturated color; should be used when the information being plotted has a critical middle value, such as topography or when the data deviates around zero.
Cyclic: change in lightness of two different colors that meet in the middle and beginning/end at an unsaturated color; should be used for values that wrap around at the endpoints, such as phase angle, wind direction, or time of day.
Qualitative: often are miscellaneous colors; should be used to represent information which does not have ordering or relationships.
Below, I have plotted the covid map using examples of the four types of colormaps.
-
The sequential map clearly works best here, as the data (the infection rate) has a natural, monotone order.
-
The diverging map is still useful. We just need to keep in mind that dark red is a high value and dark blue is a low value. The issue here, though, is that there is nothing interesting about the point in which we switch from blue to red (somewhere around 11 percent). Using the two-color scheme is not adding any new information.
-
The cyclic map is not very useful. The reader now has to keep track of light blues, purples, dark reds,...this is way too hard to interpret.
-
The qualitative map is useless in this context. There is no intuitive order to the colors and the discrete color blocks remove information from the visualization.
#https://matplotlib.org/3.1.0/tutorials/colors/colormaps.html
fig, ax = plt.subplots(2, 2, figsize=(12,10))
lkwds={'label': 'Cumulative cases per capita (percent)'}
for a, cm, t in zip(ax.reshape(-1), ['Reds', 'bwr', 'twilight', 'tab10'], ['Sequential', 'Diverging', 'Cyclic', 'Qualitative']):
map_data.plot(ax = a, column='PCT_INF', cmap=cm, legend=True)
a.set_title(t)
a.axis('off')
plt.show()

4. Axes
Axes (when applicable) are extremely important parts of visualizations and should be given with the same level of care as the rest of the figure.
Labels
- Always label your axes! The only exception I make is when one axis is obviously the date.
- Include the units your axes are measured in: percent, billions of dollars, dollars per unit,...
Ticks
The plotting package you use will add ticks and labels. Often, they are reasonable, but do not trust the default. Check the ticks and labels and make sure they are excellent.
- Do not use too many ticks and labels.
- Use easy-to-interpret tick intervals. e.g., spaced apart by 100, rather than 106
- If you need to control the limits of the axes use
ax.set_xlim(minval, maxval)
ax.set_ylim(minval, maxval)
- Set custom ticks by passing an array or list of tick values.
np.arrange()is like therange()method but takes floats instead of ints.
tick_vals = np.arange(start, end, stepsize)
ax.xaxis.set_ticks(tick_vals)
- Format the tick labels using string format codes
from matplotlib.ticker import FormatStrFormatter
ax.xaxis.set_major_formatter(FormatStrFormatter('%0.1f'))
- Rotate tick labels if they overlap (
ax.tick_paramscan do lots of things)
ax.tick_params(axis='x', labelrotation=45)
Below, I plot the cumulative covid infection rate by county for 12/31/2020. To clean up the x axis, I remove the extra space using set_xlim() and I rotate the tick labels. By setting the tick length to zero, I remove the tick. It is not conveying any useful information.
ax[1].set_xlim(-1, 72)
ax[1].tick_params(axis='x', labelrotation=90, length=0)
My next step would be to sort the bars in ascending order so it is easy to see which counties have had the most infections per capita.
fig, ax = plt.subplots(2,1, figsize=(16,12))
for a in ax:
a.bar(map_data['NAME'], map_data['PCT_INF'], color='silver')
sns.despine(ax=a)
a.set_ylabel('Cumulative cases per capita (percent)')
a.set_title('Total covid cases per capita, by Wisconsin county (12/31/2020)')
# How to find the x limits
# print(ax[0].get_xlim())
ax[1].set_xlim(-1, 72)
ax[1].tick_params(axis='x', labelrotation=90, length=0)

Summary
Wow, that was a lot of things to keep straight! Let's summarize the big points.
- Know your message, your audience, and your medium.
- Choose the figure type that best conveys your message.
- Don't clutter your figure. Make sure every mark in your figure conveys information.
- Use color to convey your message, not to make your figure "look nice."
- Use labels and text thoughtfully
Practice problems
Use markdown cells to write out your answers to the practice problems.
1. Rotating tick labels
Jeff, a friend of mine, has a rule: "The x-axis tick labels should never be rotated." His thinking is that if you need to rotate your labels, you are either using too many labels or the wrong type of chart. This rule definitely has merit.
My bar chart on covid breaks this rule. We do not want to delete some of the labels, so we should think about altering the graph type. What type of chart should you use? How does it fix the problem?
Try it at home: Copy my code for the bar graph into a new cell and modify it to create a figure that obeys Jeff's rule.
Solution: I would use a horizontal bar plot. Now the county names are on the y-axis and the labels are oriented horizontally. My readers no longer need to turn their heads sideways to read the axis.
fig, ax = plt.subplots(1,1, figsize=(12,18))
ax.barh(map_data['NAME'], map_data['PCT_INF'], color='silver')
sns.despine(ax=ax)
ax.set_xlabel('Cumulative cases per capita (percent)')
ax.set_title('Total covid cases per capita, by Wisconsin county (12/31/2020)')
ax.set_ylim(-1, 72)
plt.show()

2. Know your message.
Let's keep working on my bar chart about covid rates. I want my message to be "these counties have had high infection rates and these have had low infection rates."
How would you modify the plot to make the message clearer?
Try it at home: Modify your code to implement this change.
Solution: I would sort the bars according to the infection rate.
fig, ax = plt.subplots(1,1, figsize=(12,18))
map_data = map_data.sort_values('PCT_INF')
ax.barh(map_data['NAME'], map_data['PCT_INF'], color='silver')
sns.despine(ax=ax)
ax.set_xlabel('Cumulative cases per capita (percent)')
ax.set_title('Total covid cases per capita, by Wisconsin county (12/31/2020)')
ax.set_ylim(-1, 72)
plt.show()

3. Match the message to the plot type
The map in section 5. Maps and the bar chart above both represent the same data: The covid infection rate in WI counties. The difference is the message each plot represents.
-
Why is a bar chart not a good idea when the message is: There are covid infection clusters around Menominee, Jackson, and Dodge counties?
-
Why is a map not a good idea when the message is: Menominee, Dodge, Jackson, and Shawano are the four counties with the highest infection rates and Vernon, St. Croix, Dane, and Bayfield are the four counties with the lowest infection rates?
Solution:
-
Clustering, in this case, is about the spatial proximity of counties, which the bar chart tells me nothing about. In the bar chart, I can see that Menominee has a high infection rate, but I do not know (unless you really know WI geography) that Shawano is adjacent to Menominee.
[Although, without labels on the map, it would still be difficult to know which county is which. How might an interactive figure be useful here?]
-
The ordered bar chart makes it easy to pick off the most- and least-infected counties. In the map, I would have to look at every county and determine which ones have the darkest and lightest shades of red.